어쨋든 neural network training에서 이루고자 하는 것은
각 네트워크를 구성하는 weight 값들을 구하는 것이다.
정확하게는 (1) training input과, (2) 그에 대한 output 목표값이 주어질 때
그것으로 neural network을 구성하는 여러 노드들의 weight를 어떻게 보정해 감으로써
"최적"의 weight를 구할 수 있느냐 임.
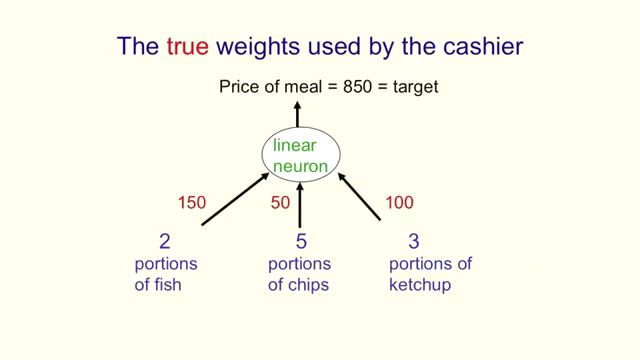
하나의 뉴런
우선 가장 단순하게 하나의 뉴런부터 시작해 보면,
E : sum of square of all residual errors. 모든 training input과 output 목표값, 즉, 실측치와 목표치의 차이를 제곱한 값들의 합.
(여러 개의 뉴런일 때는, 각각의 output node에 대해 각각 계산.)
통계에서 목표치와 실측치 차이의 수준을 판단할 때 많이 사용하며, 그 차이가 적을 수록 error는 0에 가깝게 되고, 차이가 클 수록 수는 커짐.
sum of squared residuals (SSR) 이라고 부름.
제곱의 합이기 때문에 training case의 수가 많아 질 수록, E 값이 커질 가능성이 높음.
wi : 노드의 입력 weight 중 하나. training의 대상.
z = b + w*x : 각 입력 x와 그 weight의 곱의 합. : 선형 필터.
z의 값에 대해 z값이 특정값 이상이면 1, 이하이면 0을 output하는 것을 생각할 수 있으나,
이 경우 작은 값의 차이에 의해 출력 값이 1과 0으로 너무 크게 변하게 됨.
y = 1/(1+e^-z)
z의 작은 입력 변경에 대해 큰 output 변경 문제를 개선하기 위해, smoothing함수를 사용하는데, 그중 그래프의 변화가 부드럽고, 미분이 쉽고, 미분 결과가 단순하여 1/(1+e^-z)를 많이 사용 함.
Delta rule for learning
http://darkpgmr.tistory.com/133
자신이 한치앞도 잘 안보이는 울창한 밀림에 있을 때 산 정상으로 가기 위한 방법은 간단합니다. 비록 실제 산 정상이 어디에 있는지는 모르지만 현재 위치에서 가장 경사가 가파른 방향으로 산을 오르다 보면 언젠가는 산 정상에 다다르게 될 것입니다.
또는 이와 반대로 깊은 골짜기를 찾고 싶을 때에는 가장 가파른 내리막 방향으로 산을 내려가면 될 것입니다.
그러면, weight 하나가 변할 때, 그에 따른 E의 변화율을 계산해 보면
하나의 training case에 대해서는
dE/dw = dy / dw * dE/dy = x * dE/dy 가 되며,
dE/dy는 미분하면 y(1-y)가 됨.
때문에
dE/dw = x * y(1-y)가 됨.
그런데 dE/dw를 계산하는 이유는,
이것을 dw를 결정하는데 사용할 수 있기 때문임.
r을 learning rate라 할 때,
dw = r * dE/dw = r * (x * y(1-y))
로 weight를 얼마나 변화시킬지 사용할 수 있게 됨.
즉, 하나의 뉴런의 입력 라인이 5개가 있을 때, 그중 하나의 라인의 weight의 보정은,
dE/dw 즉, w 값이 변화 할 때, E의 변화의 크기 (기울기)와 r을 곱해줘서 구하는 것으로
dE/dw가 크다는 것은 그 만큼 그 w의 변화량이 E의 변화에 크게 영향을 줌으로, 보정을 마찬가지로 그에 비례해주는 것으로, 직관적으로도 무리가 없음.
여러개 training input에 대해서는
dw = Sum (r * (x * y (1-y)))
멀티 레이어 back propagation
Layer가 h (hidden) -> i (hidden) -> j (output) 일 때,
(h와 i는 hidden layer의 노드 의미, j는 output 노드 의미)
목표는 w(h, i) (h노드에서 i노드로 이어지는 weight들의 값)이나,
그 중 우선 i와 j 관계를 살펴 보고 거기서 최종적으로 w(h, i)를 계산하는 것을 보일 수 있다.
i와 j 부터 시작하면,
우선 중요한 것이 변수들 사이의 관계다.
(w(i, j), yi) -> zj -> yj -> E
즉,
E는 yj의 함수이자, zj로도 표현될 수 있으며, wij와 yi로도 표현 될 수 있다.
yi는 zj의 함수이자, wij와 yi의 함수 이다.
zj는 wij, yi의 함수이다.
때문에 E에 대해서는
dE/dyj, dE/dzj, dE/dwij, dE/dyi 등은 가능한 미분이다.
dE/dyj 의미는 yj가 변할 때 E의 변화량 (yj가 E의 변수이므로),
dE/dzj 의미는 zj가 변할 때 E의 변화량
나머지도 마찬가지다.
역시 yj에 대해서는
dyj/dzj, dyj/dwij, dyj/dyi 등이 가능하겠지.
위에 그냥 E라고 표기하는 것은 각 노드 별로 모두 다른 값을 갖게 된다.
편의상 indexing하지 않은 것일 뿐 다 다르다.
즉 output layer의 각 node의 output과 그 기대 값은 당연히 다 다르고, 때문에 E도 다 다르다. hidden layer의 각 node의 E 역시 마찬가지다.
그럼 여러 뉴런이 함께 있는 경우는 hidden node의 dw들은 어떻게 계산 할까 ?
우선 output node는 단일 노드의 경우와 같이 dE/dw를 계산해 낼 수 있다.
그러면 그전 layer인 hidden layer의 한 뉴런의 dE/dw를 어떻게 계산할 것인가가 문제가 된다.
hidden layer의 dE/dw계산은 output layer처럼 단순하지가 않다.
왜냐하면
output 뉴런에 대해서는 그 값이 어떤 값을 가져야 하는 지에 대한 목표값이 training 자료로 주어지지만 중간에 있는
hidden layer들이 어떤 output을 내야 하는지는 사실 아무도 모른다.
때문에 대신에 hidden layer의 dE/dyi를 먼저 계산하고, 그것을 가지고 hidden layer의 dE/dw를 계산해 내는 것이다.
그럼 hidden layer의 dE/dyi를 어떻게 계산 할 것인가가 문제인데,
----------------------------------------------------------------------------------------------------------
생각해보면,
hidden layer의 yi에 따른 E의 변화율은 output layer에 각 노드에 전파되는데,
역으로 생각하면
그 output layer로 전파된 변화율의 합이 hidden layer의 한 노드의 dE/dyi라 할 수 있다.
----------------------------------------------------------------------------------------------------------
바꿔말하면,
(dE/dyi) of hidden layer = Sum for all node j in output layer는 (dzj/dyi) * (dE/dzj)
이고, (dzj/dyi)는 wij 이므로,
(dE/dyi) of hidden layer = Sum for all node j in output layer는 wij * (dE/dzj) 가 된다.
dE/dyi가 구해지면,
dE/dwij = dzj/dwij * dE/dzj 이고, dzi/dwij = yi 이므로
dE/dwij = yi * dE/dzj 이므로
dE/dzj를 이용해서 계산 가능하다.
dE/dzj = dyj/dzj * dE/dyj = y(1-y) * dE / dyj 이므로,
결국
dE/dwij는 dE/dyj로 계산 가능하고,
그 앞 hidden layer를 h layer라 하면 (h -> i -> j)
dE/dwhi는 dE/dyi를 이용해서 계산 가능하다.
이렇게 dw를 training set마다 반복적으로 업데이트 해가는 것이 back propagation이다.
* 다만, dE/dyi를 (ouput node들로의 weight 곱하기 그 노드들의 dE/dzj들의 합)이라는 것을 충분히 이해할 수 있을까 ?
참고
https://www.youtube.com/watch?v=Q0mTl9dQ4_I&t=422s
Output node의 weight는 위와 같은 delta rule을 이용해 계산 가능하다. 문제는 hidden layer의 노드들은 target 값이 없기 때문에, 위와 같은 방법으로는 계산이 불가능 하다. 그럼 어떻게 해야 할까 ?
이때 필요한 것이 Back propagation 알고리즘 이다.
Back propagation 알고리즘.
j는 output layer node 들
i는 hidden layer node 들
hidden activity : hidden layer의 output
zj는 j노드의 logit. 즉, for all i, (wij*yi + b)의 합.
yi는 hidden layer의 한 노드의 output
yj는 output layer의 한 노드의 output
아래에서 잘 이해해야 하는 것이 dE/dyi 계산 시 Summation이 추가 되는 것.












{kind=link}